
L’OCR Skill est un built-in skill d’Azure AI Search qui s’intègre nativement dans votre skillset pour extraire automatiquement le texte des images et documents via Azure AI Vision .
Introduction
L’extraction automatique de texte à partir de documents numérisés ou d’images est devenue une problématique dans les application d’entreprises qui traitent de gros volumes de documents. Azure AI Search propose une solution puissante et intégrée grâce à ses compétences cognitives (cognitive skills) pour l’extraction et l’indexation du contenu pour un usage de recherche grâce à la reconnaissance optique de caractères (OCR).
Dans cet article, nous allons explorer comment exploiter le skill OCR dans Azure AI Search en utilisant un cas d’usage d’extraction et indexation des données d’une facture .
Pourquoi un Skillset OCR dans Azure AI Search ?
Un PDF peut contenir du texte « natif » (copiable) ou seulement des images (scan). Dans le second cas, un indexeur classique ne voit rien : aucune recherche possible dans le contenu. Le Skillset OCR d’Azure AI Search résout ce problème en créant une pipeline d’enrichissement.
Notre approche cible dans cet article est simple :
- Lire les documents depuis un Blob Storage
- Générer des images normalisées par page (normalized_images)
- Appliquer l’OCR sur chaque page
- Fusionner le texte OCR avec le contenu natif du document (s’il existe)
- Indexer le texte final dans un champ interrogeable
Architecture : les 4 objets Azure AI Search
Dans Azure AI Search, une ingestion OCR se structure autour de 4 objets :
- Data source : connexion vers le container Blob qui contient les fichiers.
- Index : schéma de stockage (id, nom_fichier, texte_ocr, métadonnées…).
- Skillset : OCR + Merge (et éventuellement d’autres skills : langue, entités, PII…).
- Indexer : orchestration (lit depuis la source, exécute le skillset, écrit dans l’index).
Prérequis
Avant d’écrire le moindre code on a besoin de certains élément pour réaliser notre pipeline :
Endpoint Azure AI Search
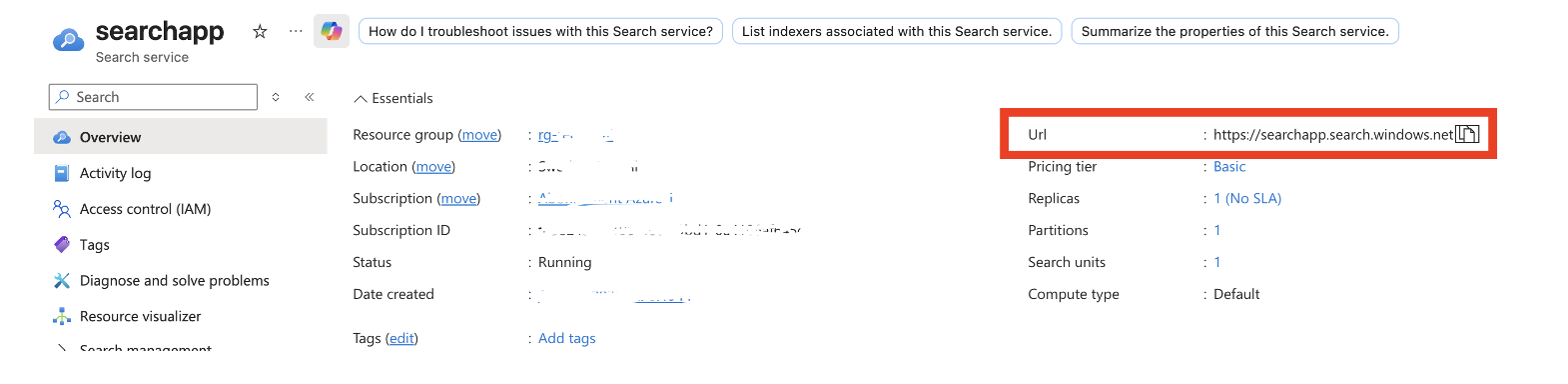
Clé admin Azure AI Search
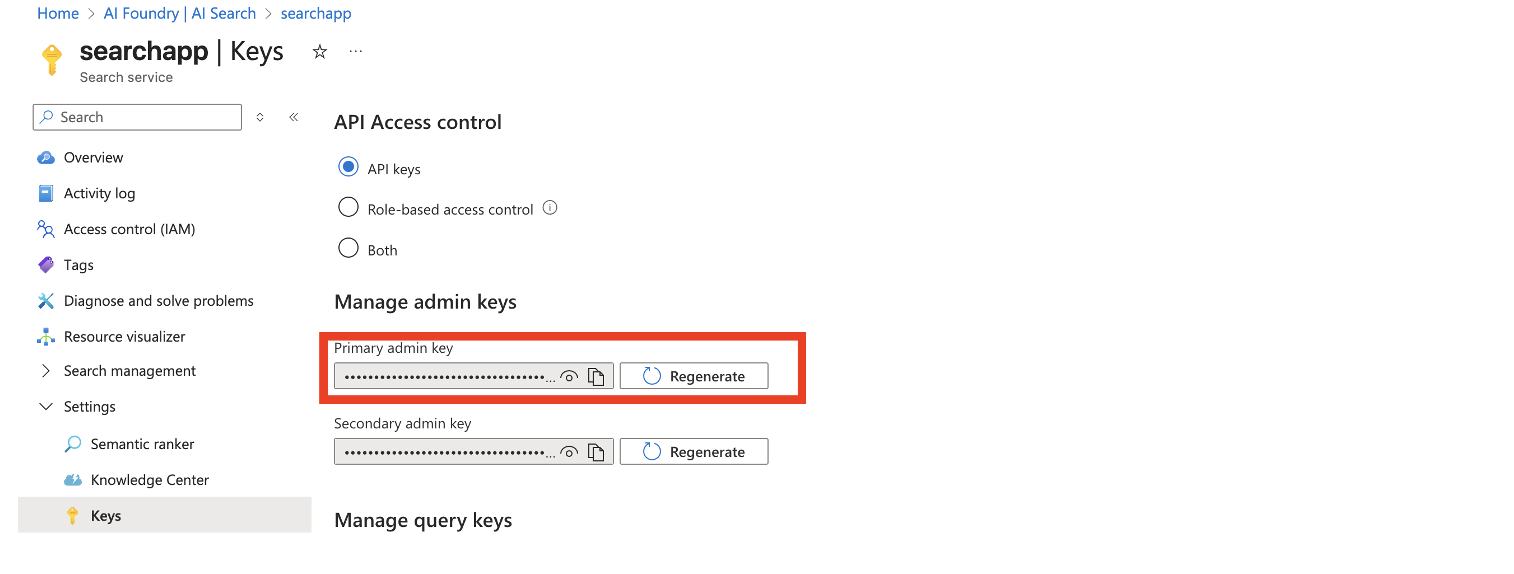
Connection string du Storage Account
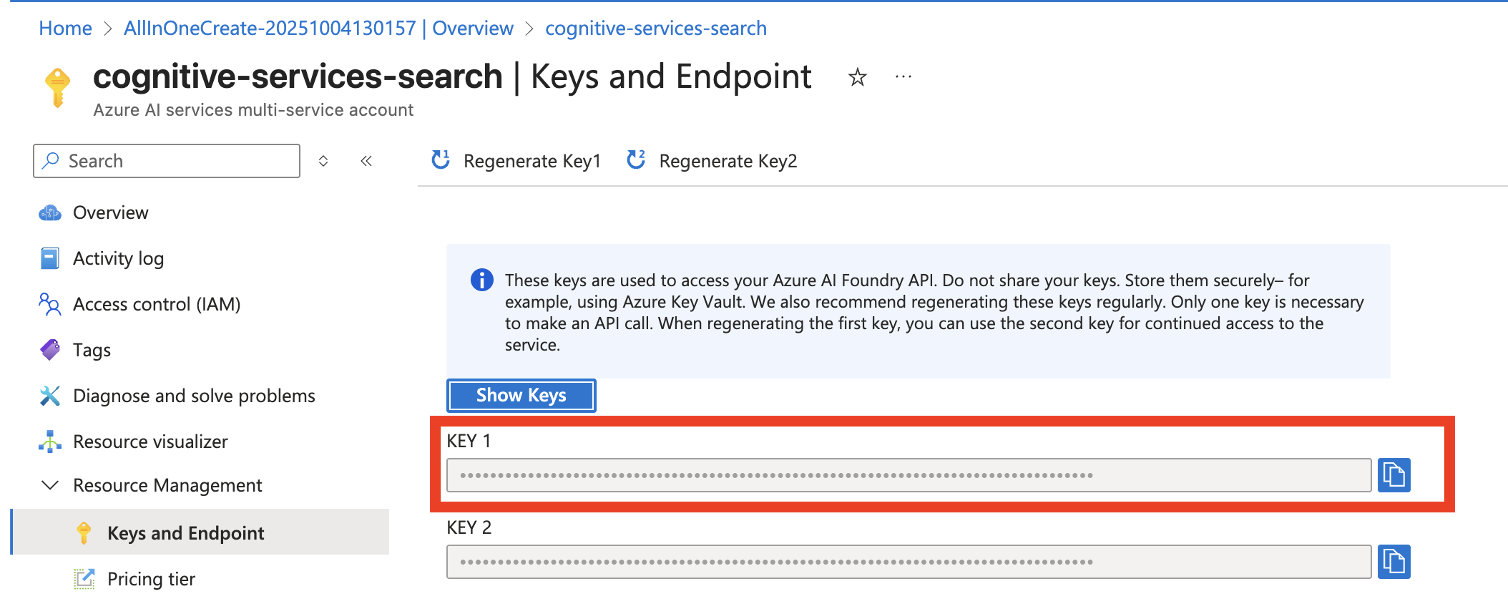
stockage
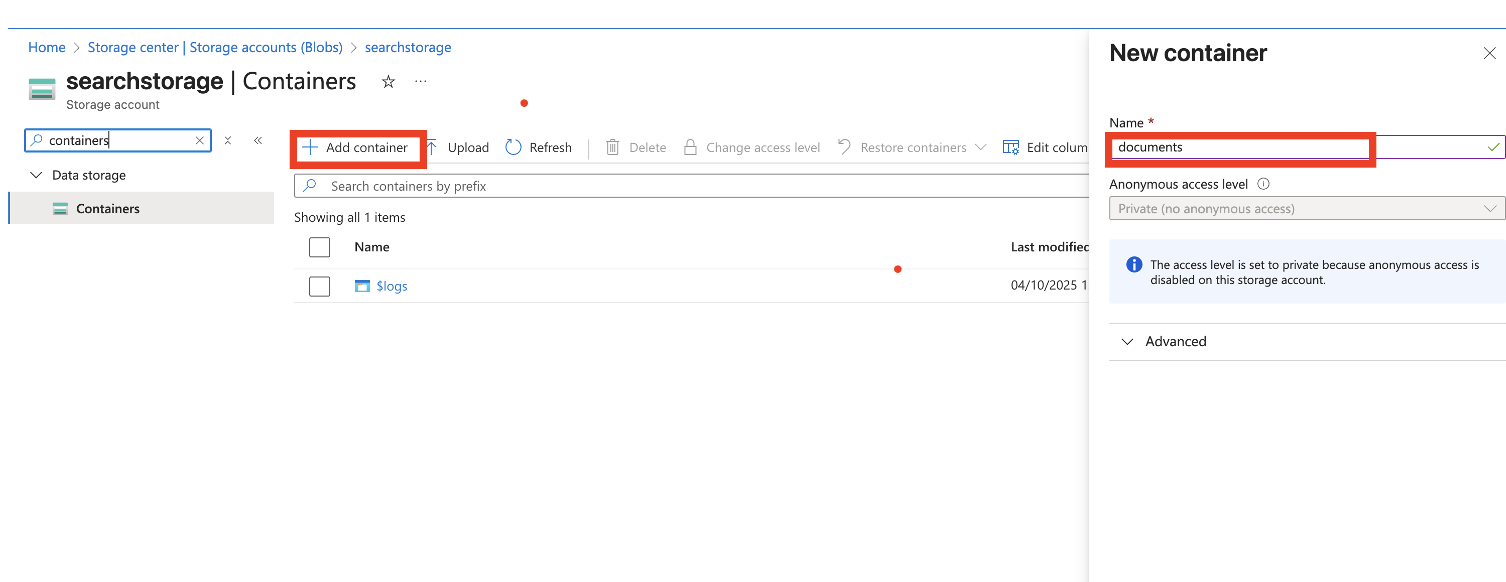
Data Source → Index → Skillset → Indexer
Datasource
La data source définit le container et la chaîne de connexion. Elle sert de point d’entrée à l’indexer.

Index
L’index reçoit les champs pour interrogation: identifiant, nom du fichier, texte final OCR, etc. Pour une première version, on garde un schéma minimal et robuste.
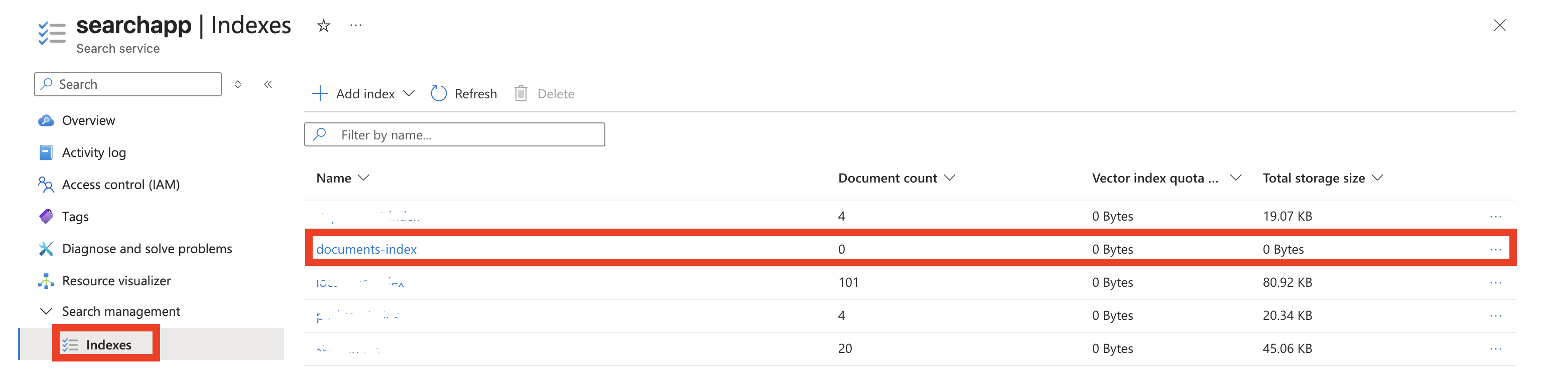
Exemple de schéma minimal :
- id (key) : identifiant stable basé sur le chemin du blob
- nom_fichier : pour afficher et filtrer
- contenu : contenu texte natif si présent (optionnel)
- texte_ocr : texte final fusionné (c’est le champ de recherche principal)
Skillset : OCR + Merge
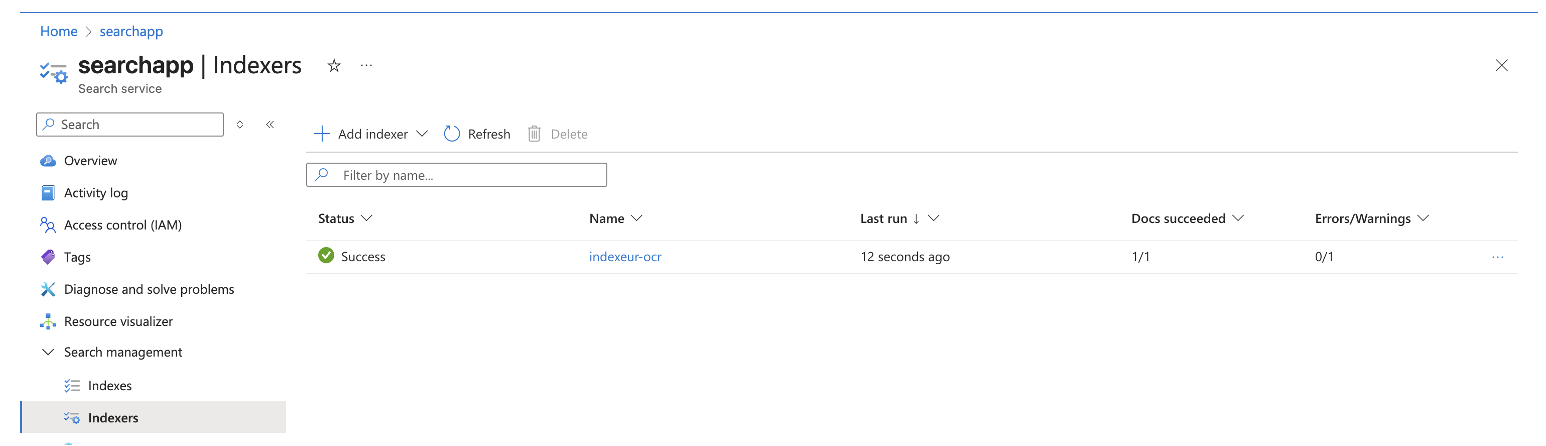
Indexer
L’indexer relie la data source, le skillset et l’index cible. Le paramètre clé pour OCR est imageAction=generateNormalizedImages.
Implémentation
Imports et clients SDK
On importe les clients qui créent/maintiennent les objets (Index, Skillset, Indexer…) et le SearchClient qui servira à la requête de validation.
from azure.core.credentials import AzureKeyCredential
from azure.search.documents.indexes import SearchIndexerClient, SearchIndexClient
from azure.search.documents.indexes.models import (
SearchIndexer,
SearchIndexerDataSourceConnection,
SearchIndexerDataContainer,
SearchIndex,
SimpleField,
SearchableField,
SearchIndexerSkillset,
OcrSkill,
MergeSkill,
InputFieldMappingEntry,
OutputFieldMappingEntry,
FieldMapping,
CognitiveServicesAccountKey,
IndexingParameters,
FieldMappingFunction,
)
from azure.search.documents import SearchClient
Configuration
Cette section contient les 4 paramètres qui font tourner le tuto :
- SEARCH_ENDPOINT : URL du service Azure AI Search.
- SEARCH_ADMIN_KEY : clé admin (nécessaire pour créer index/skillset/indexer).
- STORAGE_CONNECTION_STRING : accès au Blob Storage (où sont les PDF).
- COGNITIVE_SERVICES_KEY : clé Azure AI Services utilisée par l’OCR.
Les noms (DATA_SOURCE_NAME, INDEX_NAME…) sont simplement des identifiants lisibles pour les ressources créées dans Search.
Point clé : une query key ne suffit pas ici. Il faut une admin key, sinon vous aurez un 403 Forbidden lors de la création des objets.
SEARCH_ENDPOINT = "https://<votre-service>.search.windows.net" SEARCH_ADMIN_KEY = "<votre-cle-admin-search>" STORAGE_CONNECTION_STRING = "<votre-storage-connection-string>" COGNITIVE_SERVICES_KEY = "<votre-cle-cognitive-services>" DATA_SOURCE_NAME = "fichiers-blob" CONTAINER_NAME = "documents" INDEX_NAME = "documents-index" SKILLSET_NAME = "ocr-skillset" INDEXER_NAME = "indexeur-ocr" indexer_client = SearchIndexerClient(SEARCH_ENDPOINT, AzureKeyCredential(SEARCH_ADMIN_KEY)) index_client = SearchIndexClient(SEARCH_ENDPOINT, AzureKeyCredential(SEARCH_ADMIN_KEY))
Data source
La data source est le connecteur entre Azure AI Search et votre container Blob. À ce stade, Search « voit » la source, mais ne sait pas encore quoi stocker ni quels enrichissements exécuter.
data_source = SearchIndexerDataSourceConnection(
name=DATA_SOURCE_NAME,
type="azureblob",
connection_string=STORAGE_CONNECTION_STRING,
container=SearchIndexerDataContainer(name=CONTAINER_NAME),
)
indexer_client.create_or_update_data_source_connection(data_source)
Index
L’index est la table de destination. On y déclare :
- id — clé unique (obligatoire).
- nom_fichier — utile pour debug/affichage/filtres.
- contenu — texte natif si le PDF est textuel.
- texte_ocr — texte final interrogé (OCR + fusion).
Bon réflexe : garder un champ final (ici texte_ocr) qui contient ce que vous voulez réellement rechercher.
index = SearchIndex(
name=INDEX_NAME,
fields=[
SimpleField(name="id", type="Edm.String", key=True),
SearchableField(name="nom_fichier", type="Edm.String", filterable=True),
SearchableField(name="contenu", type="Edm.String", analyzer_name="fr.microsoft"),
SearchableField(name="texte_ocr", type="Edm.String", analyzer_name="fr.microsoft"),
],
)
index_client.create_or_update_index(index)
Skillset (OCR + Merge)
Quand un PDF est scanné, le texte n’existe pas sous forme de texte sélectionnable. L’indexer doit d’abord générer des images de pages (normalized_images). L’OCR travaille ensuite page par page sur ces images.
Paramètres clés :
- context=/document/normalized_images/* — applique le skill à chaque page image.
- image — l’image de la page.
- text (target_name=texte) — texte OCR extrait pour la page.
ocr_skill = OcrSkill(
context="/document/normalized_images/*",
default_language_code="fr",
detect_orientation=True,
inputs=[InputFieldMappingEntry(name="image", source="/document/normalized_images/*")],
outputs=[OutputFieldMappingEntry(name="text", target_name="texte")],
)
Merge : fusionner OCR + texte natif
Certains PDF contiennent déjà du texte extractible (/document/content) et aussi des zones scannées. Le MergeSkill fusionne le texte natif et le texte OCR pour produire un champ final cohérent.
merge_skill = MergeSkill(
context="/document",
insert_pre_tag=" ",
insert_post_tag=" ",
inputs=[
InputFieldMappingEntry(name="text", source="/document/content"),
InputFieldMappingEntry(name="itemsToInsert", source="/document/normalized_images/*/texte"),
InputFieldMappingEntry(name="offsets", source="/document/normalized_images/*/contentOffset"),
],
outputs=[OutputFieldMappingEntry(name="mergedText", target_name="texte_complet")],
)
Déclaration du skillset
Le skillset regroupe les skills (OCR + merge) et référence la clé Cognitive Services utilisée par les enrichissements.
skillset = SearchIndexerSkillset(
name=SKILLSET_NAME,
description="OCR sur PDF scannés + fusion avec texte natif",
skills=[ocr_skill, merge_skill],
cognitive_services_account=CognitiveServicesAccountKey(key=COGNITIVE_SERVICES_KEY),
)
indexer_client.create_or_update_skillset(skillset)
Indexer (orchestration)
L’indexer est le chef d’orchestre : il lit la data source, exécute le skillset, puis écrit le résultat dans l’index.
Le paramètre le plus important pour l’OCR :
- imageAction = generateNormalizedImages — indispensable pour créer /document/normalized_images (sinon pas d’OCR).
Les field_mappings copient des champs source (métadonnées, contenu natif) dans l’index. Les output_field_mappings copient le résultat du skillset (texte_complet) vers le champ final texte_ocr.
indexer = SearchIndexer(
name=INDEXER_NAME,
data_source_name=DATA_SOURCE_NAME,
target_index_name=INDEX_NAME,
skillset_name=SKILLSET_NAME,
parameters=IndexingParameters(
configuration={
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages", # indispensable pour OCR
}
),
field_mappings=[
FieldMapping(
source_field_name="metadata_storage_path",
target_field_name="id",
mapping_function=FieldMappingFunction(
name="base64Encode",
parameters={"useHttpServerUtilityUrlTokenEncode": True},
),
),
FieldMapping(source_field_name="metadata_storage_name", target_field_name="nom_fichier"),
FieldMapping(source_field_name="content", target_field_name="contenu"),
],
output_field_mappings=[
FieldMapping(source_field_name="/document/texte_complet", target_field_name="texte_ocr"),
],
)
indexer_client.create_or_update_indexer(indexer)
Pourquoi encoder metadata_storage_path en base64 ? Parce que c’est un identifiant unique et stable pour chaque blob, pratique comme clé id.
On déclenche l’indexer pour indexer les documents et produire le texte OCR dans l’index.
indexer_client.run_indexer(INDEXER_NAME)
Conclusion
Mettre en place un skillset OCR dans Azure AI Search permet de transformer des PDF scannés en contenus réellement interrogeables, au même titre que n’importe quelle source textuelle. Le principe essentiel à retenir est le suivant : Data Source → Index → Skillset → Indexer, puis un run et une requête de validation afin de confirmer que le champ final (par exemple texte_ocr) est correctement alimenté.
Une fois cette base en place, plusieurs extensions deviennent naturelles : enrichir les documents (détection de langue, extraction d’entités, classification), renforcer l’usage des métadonnées pour filtrer par type, date ou tenant, ou encore construire un RAG au-dessus de l’index (avec citations) afin d’interroger le corpus en langage naturel. En production, il est recommandé de conserver une pipeline observable et maîtrisée : supervision des exécutions d’indexer, rotation des clés, et maintien d’un schéma d’index stable dans le temps.
Avec cette mise en œuvre, vous disposez désormais d’une fondation solide pour indexer des documents scannés et les rendre exploitables dans un moteur de recherche moderne, tout en ouvrant la voie à des cas d’usage GenAI plus avancés sur votre patrimoine documentaire.
